




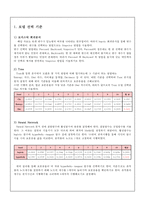


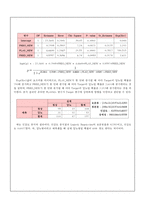

 분야
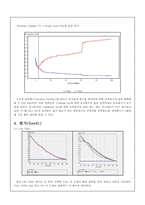
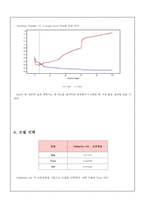
분야-Validation Set의 오분류율
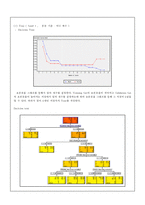
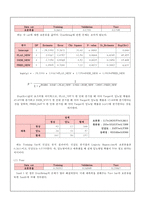
2. 모델 선택(Seed1)
-Tree
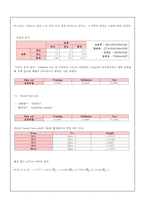
3. 분석(Seed1)
4. 평가(Seed1)
- Regression / Tree / Neural Network
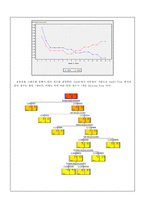
5. 분석(Seed3)
6. 모델 선택(Seed3)
-Tree
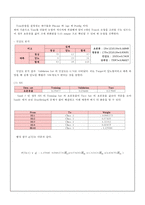
7. 평가(Seed3)
- Regression / Tree / Neural Network
1. 모델 선택 기준
1) 로지스틱 회귀분석
해당 자료는 타겟 변수가 당뇨병의 여부를 나타내는 범주형이다. 따라서 logstic 회귀분석을 통해 변수를 선택한다. 변수를 선택하는 방법으로는 Stepwise 방법을 사용한다.
변수 선택의 방법에는 Forward. Backward, Stepwise가 있다. Forward의 경우에는 한 번 선택된 변수가 제거되지 않는 단점이 존재하고, Backward는 한 번 제외된 변수의 재선택이 불가하고 변수 개수가 많을 경우 다루기 힘들다는 단점이 존재한다. 따라서 Forward 와 Backward 의 방법을 동시에 갖는 매단계마다 선택과 제거를 반복하는 Stepwise 방법을 사용하기로 한다.
2) Tree
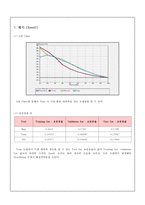
Tree를 통한 분석에서 모델은 몇 가지 방법에 의해 평가되는데 그 기준이 되는 방법에는
Entropy 지수, Gini 지수, 카이제곱 통계량, Deviance 등 이 있다. 어떤 기준을 선택하여 Tree 분석을 할지 결정키 위해 위의 기준들을 이용해 반복적으로 오분류율을 구해보았다.
- 오늘 본 자료가 없습니다.
- (A+) [인간관계론] 4주 1강에서 매슬로우의 욕구 5단계에 대해 학습하였습니다. 개인행동은 일반적으로 특정 시점에서 가장 강한 욕구에 의해서 결정된다고 매슬로우는 정의하였습니다. 매슬로우의 욕구 이론을 본인의 상황에 맞게 설명 한 후, 욕구이론의 장단점을 제시해 봅시다.
- [경제학개론 A+받은자료] 수요곡선과 공급곡선이 일반적인 경우 수요의 가격탄력성이 공급에 비해 비탄력적인 경우 소주에 조세를 부과하면 소주시장에 어떤 변화가 있는지 다음 질문에 답해봅시다.
- 쿠팡 마케팅 4P전략과 쿠팡 SWOT,STP분석 및 쿠팡 기업현황과 미래전략방향 제시
- 경영전략론_1 산업의 수익을 결정하는 마이클 포터의 5force에 대하여 특정 산업의 예를 들어 설명하시오 2 핵심역량을 결정하는 3가지 요인과 핵심역량 전략에 관하여 사례를 통하여 설명하시오 3 4차 산업혁명에 따른 제품(product) 일하는 과정(process) 요구하는 사람과 깅버문화(people)가 어떻게 변화하여야 하는지에 관한
- [벤처기업][벤처][기업][벤처기업 정의][벤처기업 특징]벤처기업의 정의, 벤처기업의 특징, 벤처기업의 선정범위, 벤처기업의 경제적 효과, 벤처기업의 성장과정, 벤처기업의 기업가정신, 벤처기업의 합병 분석
해당 정보 및 게시물의 저작권과 기타 법적 책임은 자료 등록자에게 있습니다. 위 정보 및 게시물 내용의 불법적 이용,무단 전재·배포는 금지되어 있습니다. 저작권침해, 명예훼손 등 분쟁요소 발견 시 고객센터에 신고해 주시기 바랍니다.


