1. 들어가며
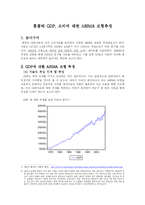
홍콩의 GDP자료와 민간 소비자료를 분석하여 적절한 ARIMA 모형을 추정해보고자 한다. 자료는 1973년 1/4분기부터 2004년 4/4분기 까지 128개의 계절조정이 안된 분기별 자료이며, 2000년 가격으로 계측된 실질 GDP와 실질 소비 자료의 출처는 다음과 같다. http://www.censtatd.gov.hk/hong_kong_statistics/statist
ARIMA 시계열분석 Process를 따라 수행된 결과를 제시 할 것이다.
* SAS Code
(1) sas data set 생성
DATA Elec;
INPUT Elec;
DATE=INTNX('MONTH', '1JAN95'D, _N_-1);
FORMAT DATE MONYY.;
lelec=log(elec);
lelec12=dif12(lelec);
lelec1=dif1(lelec);
lelec121=dif1(lelec12);
RUN;
(2) 시계열그림 그리기
SYMBOL I=JOIN V=DOT H=1 L
ARIMA), 두 번째가 통계적 자료 분석에 가장 흔히 사용되는 다중회귀분석(multiple regression), 세 번째가 신경망 알고리즘이다.
ARIMA와 중회귀 분석에는 Box-Jenkins의 모형화 방법(모형식별, 모수추정, 모형진단, 예측)과 같은 과정을 거쳐 예측에 이용한다. 신경망 분석은 적합한 입력변수를 선택한 다음
ARIMA(0,1,1)을 선택하였다. 그러나, 모수 추정을 한 뒤, 잔차분석을 통해 모형을 진단해본 결과, ARIMA(0,1,1)모형은 적합하지 않았다. 적합한 모형을 찾기 위해 다시 ARIMA(1,1,0) 모형과 ARIMA(1,1,1) 모형을 선택하여 모수 추정과 잔차분석을 해보았으나, 계속해서 잔차의 기본가정이 만족되지 않음을 볼 수 있었다
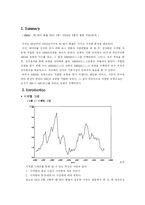
그 결과는 위의 <그림1>과 같이 1971년부터 꾸준히 증가하다가 1998년에 배출량이 급격하게 감소하고 다시 상승하는 곡선을 가지는 것을 알 수 있다. 이러한 변화 양상으로 보아 배출량은 꾸준히 증가하여 2010년 배출량은 2007년보다 클 것이라고 예상을 할 수 있다.
본격적으로 ARIMA분석을 시작하기 위해