통계량은 2명의 평균 성적이다. 여기서는 표본평균, 표본분산, 표본평균의 평균, 표본평균의 분산을 구분할 수 있어야 한다.
학생
1
2
3
4
5
모평균
모분산
성적
40
40
80
50
60
60
200
표기
X1
X2
X3
X4
X5
μ
σ2
<표1>
표본
1
2
3
4
5
6
7
8
9
10
표본평균의 평균
표본평균의 분산
표본학생
통계량X2의 계산
귀무가설이 옳다는 가정하에 기대빈도를 계산하고 이 값과 실제로 관측한 빈도를 이용하여 검정통계량X2값을 계산한다.
X2=(1-13)2/13+(40-32)2/32+…… + (1-5)2/5
= 32.5538
절차 4: 자유도의 계산
분할표의 칸의 수에 따라 자유도는 결정된다.
자유도 = (행의 수 - 1) × (열의 수 –
4.1 개요
1980년대와 1990년대에 걸쳐서 미국기업의 지대한 관심을 모은 것은 품질개선이었다. 20세기 중반에 시작된 일본의 ‘산업기적’에 관한 많은 토론과 글들이 발표되었다. 일본은 미국이나 그 밖의 다른 나라와는 달리 고품질 제품의 생산을 위한 기업 내의 분위기를 창출하는데 성공하였다. 일
Ⅰ. 기업 부실예측
1. 단일변량 부실예측모형
1) 모형
단일변량 부실예측모형(Univariate model of distress prediction)은 단 한 개의 재무비율 또는 변수를 이용하여 기업부실을 예측하는 모형으로 比率分布의 差異分析과 二分類檢定으로 구성된다.
비율분포의 차이분석은 기업의 부실화과정의 진행에 따
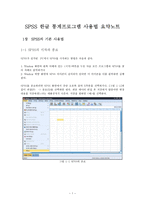
①컨트롤 메뉴 버튼으로 이 버튼을 선택하면 SPSS 화면을 조정할 수 있는 메뉴가 나타난다.
②화면의 가장 위에 위치한 제목 표시줄은 SPSS 창의 이름과 파일 이름을 표시한다. 초기화면에서는 SPSS 데이터 편집기 창이 보여지며, 현재 자료를 저장하지 않았기 때문에 제목없음으로 나타난다.
③제목 표시