한글을 연속된 공간에 가나다라 순서로 '가'에서 'ᄒ'까지를 코드화하는 방식이 유니코드 기술 위원회(UTC)에서 채택한 유니코드 2.0 규격이다.
이전의 한글코드는 완성형 방식이었다. 완성형이란 2바이트의 코드를 할당해서 하나의 16진수에 하나의 글자를 할당하는 방식이다. 완성형 방식의 코드는
완성형을 제정하게 되는 가장 중요한 이유는 KS완성형코드에서 처리할 수 없었던 현대어 8822자를 처리하기 위한 것이고, 제정 원칙은 기존의 완성형만을 지원하는 프로그램 및 데이터와의 호환성을 유지한다는 것이다. 여기서 확장 완성형이 비판을 받게 되는 이유는 호환성을 위해서 한글 순서(사전
Ⅱ. 데이터베이스와 데이터베이스관리시스템
1. 데이터베이스(DB : Data Base)
1) 개념
복수의 사용자를 위해서 운용될 수 있는 자료를 저장하고 서로 연관된 정보에 대하여 최소한의 중복만을 허용하여 모아놓은 자료의 집합을 말한다. 즉, 특정 조직의 공동업무에 필요한 데이터를 완벽화, 비중복화,
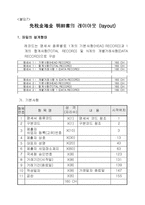
코드 형태에서 키를 지정
⑥ 무결성 조건 지정
⑦ 데이터 접근에 대한 규칙 규정
2) DML(Data Manipulation Language)이 구현하는 기능
(1) 사용자와 DBMS간의 인터페이스의 중요부분
(2) 인터페이스를 위한 데이터 조작 기능의 조건
① 사용하기 쉽고 자연어에 가까워야 한다.
② 정확하고 완전해야
I. 서론
한글 부호 체계는 우리 민족의 문자, 우리 민족이 사용하고 있는 문자를 전산 체계화한 것을 말한다. 이 자료는 95년 11월 현재까지 제안된 한글 부호화 체계를 정리 나열하고, 국제 표준인 ISO-2022, ISO-10646과의 관계를 설명한 A+ 레포트이다.
II. 본론
1. 한글 부호체계
(1) 완성형한글코드 :