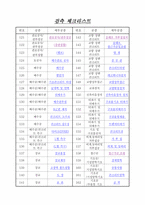
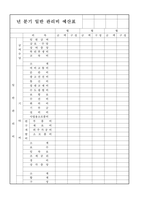
연관성이 의미 있다고 말하기는 곤란하다.
특히 대용량 데이터를 다루는 데이터마이닝의 경우, 수많은 품목들의 관계속에서 의미있는 관련성을 찾기 위해서는 결과해석에 앞서 연관성의 내용이 일반화 할 수 있는 내용인가를 판단할 수 있도록 각 연관규칙을 비교할 수 있는 비교기준이 필요하다.
대용량의 데이터의 이들 데이터 내에 존재하는 관계, 패턴, 규칙 등을 담색하고 찾아내어 모형 화함으로써 유용한 지식을 추출하는 일련의 과정들 또는 대용량 데이터에 대한 탐색 적 데이터 분석(Exploratory Data Analysis)이라고 할 수 있다.
좀 더 간단하게 말하자면 많은 데이터 가운데 숨겨져 있는 유용
데이터마이닝은 중요한 패턴이나 경향을 추출하기 위한 목적으로 데이터를 체계적으로 개발하는 것으로 정의된다. 많은 기업에서는 정보기술의 향상과 데이터 저장 비용의 하락으로 대용량의 데이터를 저장 할 수 있다. 방대하고 복잡해진 데이터를 효과적으로 활용하는 방안이 최대 관심이다. 경영
I. 데이터마이팅의 기본개념
1) 데이터마이닝의 기본개념
데이터마이닝이란 자동화되고 지능을 갖춘 데이터베이스 분석기법으로 90년대 초반부터 지식발견(KDD: Knowledge Discovery in Database), 정보발견(information discovery), 정보수확(information harvesting)의 이름으로도 소개되어 왔는데 일반적으로 "대량의 데
I. 데이터마이팅의 기본개념
1) 데이터마이닝의 기본개념
데이터마이닝이란 자동화되고 지능을 갖춘 데이터베이스 분석기법으로 90년대 초반부터 지식발견(KDD: Knowledge Discovery in Database), 정보발견(information discovery), 정보수확(information harvesting)의 이름으로도 소개되어 왔는데 일반적으로 "대량의 데