정보자원의 뜻을 이해하고,
논리적 추론까지 할 수 있는 차세대 지능형 웹
시멘틱 웹의 탄생배경
90년대 말에 사람과 사람의 정보공간으로서의 웹이 성숙단계에 이름
웹을 사람과 기계, 그리고 기계와 기계의 공간으로 만드는 제2단계 웹에 대한 노력으로 시작하게 됨
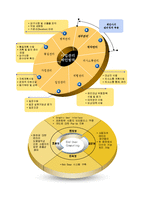
온톨로지(Ontology)
문서의 일부 자원일 수도 있다.
②속성 (Property)
자원을 표현하는 속성은 특정한 의미를 가지며 허용되는 값, 특성이 기술하는 자원의 유형, 다른 속성과의 관계를 정의한다. 속성유형은 ‘저자’나 ‘제목’ 등과 같이 자원의 속성을 적절한 이름으로 표현한 것으로, 속성 유형 자체가 하나의 자원이
문서가 나온다. 대개 이런 경우 많은 부분이 불필요한 정보이므로 검색자는 문서 하나하나를 열어 확인하면서 원하는 정보를 재차 확인해야하는 번거로움을 감내해야 한다. 결국엔 사람이 눈으로 보고 이해해야 하는 웹인 셈이다. 여기서 한발 더 나아간 개념이 ‘생각하는 웹’, 시멘틱 웹이다. 텍스
정보들은 그 내용 또한 기계가 이해하기에 어려운 점이 많다. 이러한 시장환경과 정보기술상의 어려움을 극복하기 위해서는 비용요소를 줄일 수 있는 자기기술적(self-describing) 규약이나 소프트웨어 설계 방법들이 필요하며, 그중 의미론적인 통합을 위한 온톨로지(Ontology)의 구축에 대한 필요성이 제기
기계학습 기반 및 통계적 자연어 처리 기법이 주류를 이뤘다. 하지만 최근에는 딥 러닝과 딥 러닝 기반의 자연어처리가 방대한 텍스트로부터 의미 있는 정보를 추출하고 활용하기 위한 언어처리 연구 개발이 전 세계적으로 활발히 진행되고 있다. 본 과제에서는 자연언어처리와 컴퓨터 언어학에 대해